This document gives an overview of how Aurora works under the hood. It assumes you’ve already worked through the “hello world” example job in the Aurora Tutorial. Specifics of how to use Aurora are not given here, but pointers to documentation about how to use Aurora are provided.
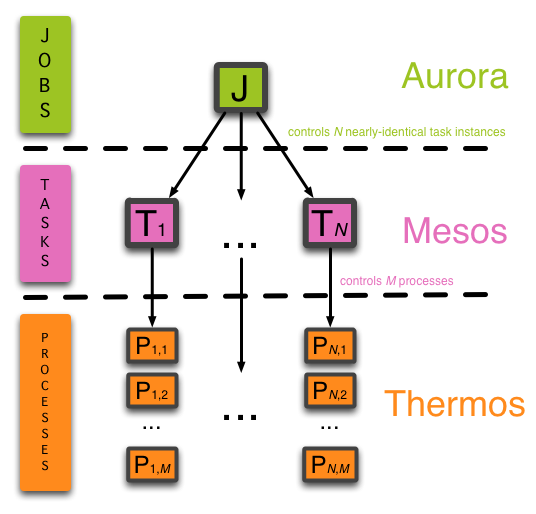
Aurora is a Mesos framework used to schedule jobs onto Mesos. Mesos
cares about individual tasks, but typical jobs consist of dozens or
hundreds of task replicas. Aurora provides a layer on top of Mesos with
its Job abstraction. An Aurora Job consists of a task template and
instructions for creating near-identical replicas of that task (modulo
things like “instance id” or specific port numbers which may differ from
machine to machine).
How many tasks make up a Job is complicated. On a basic level, a Job consists of one task template and instructions for creating near-idential replicas of that task (otherwise referred to as “instances” or “shards”).
However, since Jobs can be updated on the fly, a single Job identifier or job key can have multiple job configurations associated with it.
For example, consider when I have a Job with 4 instances that each
request 1 core of cpu, 1 GB of RAM, and 1 GB of disk space as specified
in the configuration file hello_world.aurora. I want to
update it so it requests 2 GB of RAM instead of 1. I create a new
configuration file to do that called new_hello_world.aurora and
issue a aurora update start <job_key_value>/0-1 new_hello_world.aurora
command.
This results in instances 0 and 1 having 1 cpu, 2 GB of RAM, and 1 GB of disk space, while instances 2 and 3 have 1 cpu, 1 GB of RAM, and 1 GB of disk space. If instance 3 dies and restarts, it restarts with 1 cpu, 1 GB RAM, and 1 GB disk space.
So that means there are two simultaneous task configurations for the same Job at the same time, just valid for different ranges of instances.
This isn’t a recommended pattern, but it is valid and supported by the Aurora scheduler. This most often manifests in the “canary pattern” where instance 0 runs with a different configuration than instances 1-N to test different code versions alongside the actual production job.
A task can merely be a single process corresponding to a single
command line, such as python2.6 my_script.py. However, a task can also
consist of many separate processes, which all run within a single
sandbox. For example, running multiple cooperating agents together,
such as logrotate, installer, master, or slave processes. This is
where Thermos comes in. While Aurora provides a Job abstraction on
top of Mesos Tasks, Thermos provides a Process abstraction
underneath Mesos Tasks and serves as part of the Aurora framework’s
executor.
You define Jobs,Tasks, and Processes in a configuration file.
Configuration files are written in Python, and make use of the Pystachio
templating language. They end in a .aurora extension.
Pystachio is a type-checked dictionary templating library.
TL;DR
- Aurora manages jobs made of tasks.
- Mesos manages tasks made of processes.
- Thermos manages processes.
- All defined in
.auroraconfiguration file.
Each Task has a sandbox created when the Task starts and garbage
collected when it finishes. All of a Task's processes run in its
sandbox, so processes can share state by using a shared current working
directory.
The sandbox garbage collection policy considers many factors, most
importantly age and size. It makes a best-effort attempt to keep
sandboxes around as long as possible post-task in order for service
owners to inspect data and logs, should the Task have completed
abnormally. But you can’t design your applications assuming sandboxes
will be around forever, e.g. by building log saving or other
checkpointing mechanisms directly into your application or into your
Job description.
When Aurora reads a configuration file and finds a Job definition, it:
Job definition.Job into its constituent Tasks.Tasks to the scheduler.Tasks into PENDING state, starting each
Task’s life cycle.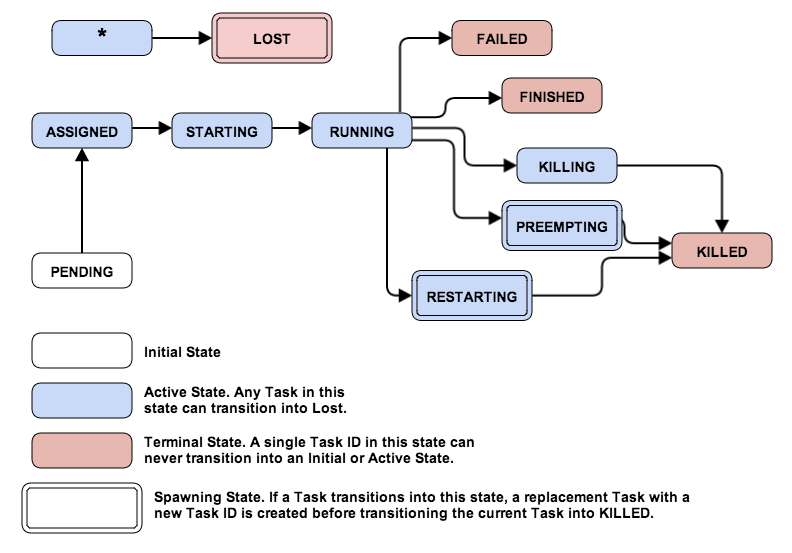
When a Task is in the PENDING state, the scheduler constantly
searches for machines satisfying that Task’s resource request
requirements (RAM, disk space, CPU time) while maintaining configuration
constraints such as “a Task must run on machines dedicated to a
particular role” or attribute limit constraints such as “at most 2
Tasks from the same Job may run on each rack”. When the scheduler
finds a suitable match, it assigns the Task to a machine and puts the
Task into the ASSIGNED state.
From the ASSIGNED state, the scheduler sends an RPC to the slave
machine containing Task configuration, which the slave uses to spawn
an executor responsible for the Task’s lifecycle. When the scheduler
receives an acknowledgement that the machine has accepted the Task,
the Task goes into STARTING state.
STARTING state initializes a Task sandbox. When the sandbox is fully
initialized, Thermos begins to invoke Processes. Also, the slave
machine sends an update to the scheduler that the Task is
in RUNNING state.
If a Task stays in ASSIGNED or STARTING for too long, the
scheduler forces it into LOST state, creating a new Task in its
place that’s sent into PENDING state. This is technically true of any
active state: if the Mesos core tells the scheduler that a slave has
become unhealthy (or outright disappeared), the Tasks assigned to that
slave go into LOST state and new Tasks are created in their place.
From PENDING state, there is no guarantee a Task will be reassigned
to the same machine unless job constraints explicitly force it there.
If there is a state mismatch, (e.g. a machine returns from a netsplit
and the scheduler has marked all its Tasks LOST and rescheduled
them), a state reconciliation process kills the errant RUNNING tasks,
which may take up to an hour. But to emphasize this point: there is no
uniqueness guarantee for a single instance of a job in the presence of
network partitions. If the Task requires that, it should be baked in at
the application level using a distributed coordination service such as
Zookeeper.
Job configurations can be updated at any point in their lifecycle.
Usually updates are done incrementally using a process called a rolling
upgrade, in which Tasks are upgraded in small groups, one group at a
time. Updates are done using various Aurora Client commands.
For a configuration update, the Aurora Client calculates required changes by examining the current job config state and the new desired job config. It then starts a rolling batched update process by going through every batch and performing these operations:
The Aurora client continues through the instance list until all tasks are
updated, in RUNNING, and healthy for a configurable amount of time.
If the client determines the update is not going well (a percentage of health
checks have failed), it cancels the update.
Update cancellation runs a procedure similar to the described above update sequence, but in reverse order. New instance configs are swapped with old instance configs and batch updates proceed backwards from the point where the update failed. E.g.; (0,1,2) (3,4,5) (6,7, 8-FAIL) results in a rollback in order (8,7,6) (5,4,3) (2,1,0).
The Executor implements a protocol for rudimentary control of a task via HTTP. Tasks subscribe for
this protocol by declaring a port named health. Take for example this configuration snippet:
nginx = Process(
name = 'nginx',
cmdline = './run_nginx.sh -port {{thermos.ports[http]}}')
When this Process is included in a job, the job will be allocated a port, and the command line will be replaced with something like:
./run_nginx.sh -port 42816
Where 42816 happens to be the allocated. port. Typically, the Executor monitors Processes within
a task only by liveness of the forked process. However, when a health port was allocated, it will
also send periodic HTTP health checks. A task requesting a health port must handle the following
requests:
| HTTP request | Description |
|---|---|
GET /health |
Inquires whether the task is healthy. |
POST /quitquitquit |
Task should initiate graceful shutdown. |
POST /abortabortabort |
Final warning task is being killed. |
Please see the configuration reference for configuration options for this feature.
If you need to pause your health check, you can do so by touching a file inside of your sandbox,
named .healthchecksnooze
As long as that file is present, health checks will be disabled, enabling users to gather core dumps or other performance measurements without worrying about Aurora’s health check killing their process.
WARNING: Remember to remove this when you are done, otherwise your instance will have permanently disabled health checks.
The Executor follows an escalation sequence when killing a running task:
health port is not present, skip to (5)kill)kill -9)If the Executor notices that all Processes in a Task have aborted during this sequence, it will not proceed with subsequent steps. Note that graceful shutdown is best-effort, and due to the many inevitable realities of distributed systems, it may not be performed.
Sometimes a Task needs to be interrupted, such as when a non-production
Task’s resources are needed by a higher priority production Task. This
type of interruption is called a pre-emption. When this happens in
Aurora, the non-production Task is killed and moved into
the PREEMPTING state when both the following are true:
PENDING production task that hasn’t been
scheduled due to a lack of resources.Since production tasks are much more important, Aurora kills off the
non-production task to free up resources for the production task. The
scheduler UI shows the non-production task was preempted in favor of the
production task. At some point, tasks in PREEMPTING move to KILLED.
Note that non-production tasks consuming many resources are likely to be preempted in favor of production tasks.
A RUNNING Task can terminate without direct user interaction. For
example, it may be a finite computation that finishes, even something as
simple as echo hello world.Or it could be an exceptional condition in
a long-lived service. If the Task is successful (its underlying
processes have succeeded with exit status 0 or finished without
reaching failure limits) it moves into FINISHED state. If it finished
after reaching a set of failure limits, it goes into FAILED state.
You can terminate a Task by issuing an aurora job kill command, which
moves it into KILLING state. The scheduler then sends the slave a
request to terminate the Task. If the scheduler receives a successful
response, it moves the Task into KILLED state and never restarts it.
The scheduler has access to a non-public RESTARTING state. If a Task
is forced into the RESTARTING state, the scheduler kills the
underlying task but in parallel schedules an identical replacement for
it.
You define and configure your Jobs (and their Tasks and Processes) in
Aurora configuration files. Their filenames end with the .aurora
suffix, and you write them in Python making use of the Pystachio
templating language, along
with specific Aurora, Mesos, and Thermos commands and methods. See the
Configuration Guide and Reference and
Configuration Tutorial.
It is possible for the Aurora executor to announce tasks into ServerSets for the purpose of service discovery. ServerSets use the Zookeeper group membership pattern of which there are several reference implementations:
These can also be used natively in Finagle using the ZookeeperServerSetCluster.
For more information about how to configure announcing, see the Configuration Reference.
You create and manipulate Aurora Jobs with the Aurora client, which starts all its
command line commands with
aurora. See Aurora Client Commands for details
about the Aurora Client.
You interact with Aurora jobs either via:
Part of the output from creating a new Job is a URL for the Job’s scheduler UI page.
For example:
vagrant@precise64:~$ aurora job create devcluster/www-data/prod/hello \
/vagrant/examples/jobs/hello_world.aurora
INFO] Creating job hello
INFO] Response from scheduler: OK (message: 1 new tasks pending for job www-data/prod/hello)
INFO] Job url: http://precise64:8081/scheduler/www-data/prod/hello
The “Job url” goes to the Job’s scheduler UI page. To go to the overall scheduler UI page,
stop at the “scheduler” part of the URL, in this case, http://precise64:8081/scheduler
You can also reach the scheduler UI page via the Client command aurora job open:
aurora job open [<cluster>[/<role>[/<env>/<job_name>]]]
If only the cluster is specified, it goes directly to that cluster’s scheduler main page. If the role is specified, it goes to the top-level role page. If the full job key is specified, it goes directly to the job page where you can inspect individual tasks.
Once you click through to a role page, you see Jobs arranged separately by pending jobs, active jobs, and finished jobs. Jobs are arranged by role, typically a service account for production jobs and user accounts for test or development jobs.
See client commands.